

The “Claude Went Dumb” Incident: A Post-Mortem

From March through April 2026, Claude got noticeably worse.
The products affected—Claude Code, Claude Agent SDK, and Claude Cowork—degraded for roughly 47 days. Developers felt it concretely: the model started forgetting things, failing to recognize code it had written just moments before; its reasoning grew shallower, causing frequent failures on complex tasks; and token consumption accelerated, with usage quotas mysteriously running out ahead of schedule.
On April 2, Stella Laurenzo, Senior Director at AMD AI, published an independent audit on GitHub: 6,852 sessions, 234,760 tool calls, spanning three months. Her conclusion: the reasoning depth of Claude Code had dropped 73% between January and March; the average number of file reads per task fell from 6.6 to 2; and task failure retries increased 80-fold. That data put an end to any remaining debate about whether users were collectively imagining things.
User complaints went largely unacknowledged. Anthropic made no public admission. On April 23—the same day OpenAI shipped GPT-5.5—Anthropic published a post-incident report, formally acknowledged the three issues, and reset usage quotas for all subscribers.
The three engineering explanations Anthropic offered are technically coherent; there’s no reason to call them fabrications.
But three threads of circumstantial evidence make the explanation feel incomplete: two of the three changes objectively reduced compute consumption—the alignment of direction is too tidy; the change that required the least engineering effort took the longest to fix; and Anthropic’s public acknowledgment came exactly three days after a major compute capacity deal was signed.
Our read: compute scarcity was likely a material backdrop to this incident—not merely three isolated engineering mishaps.
I. What Anthropic Said
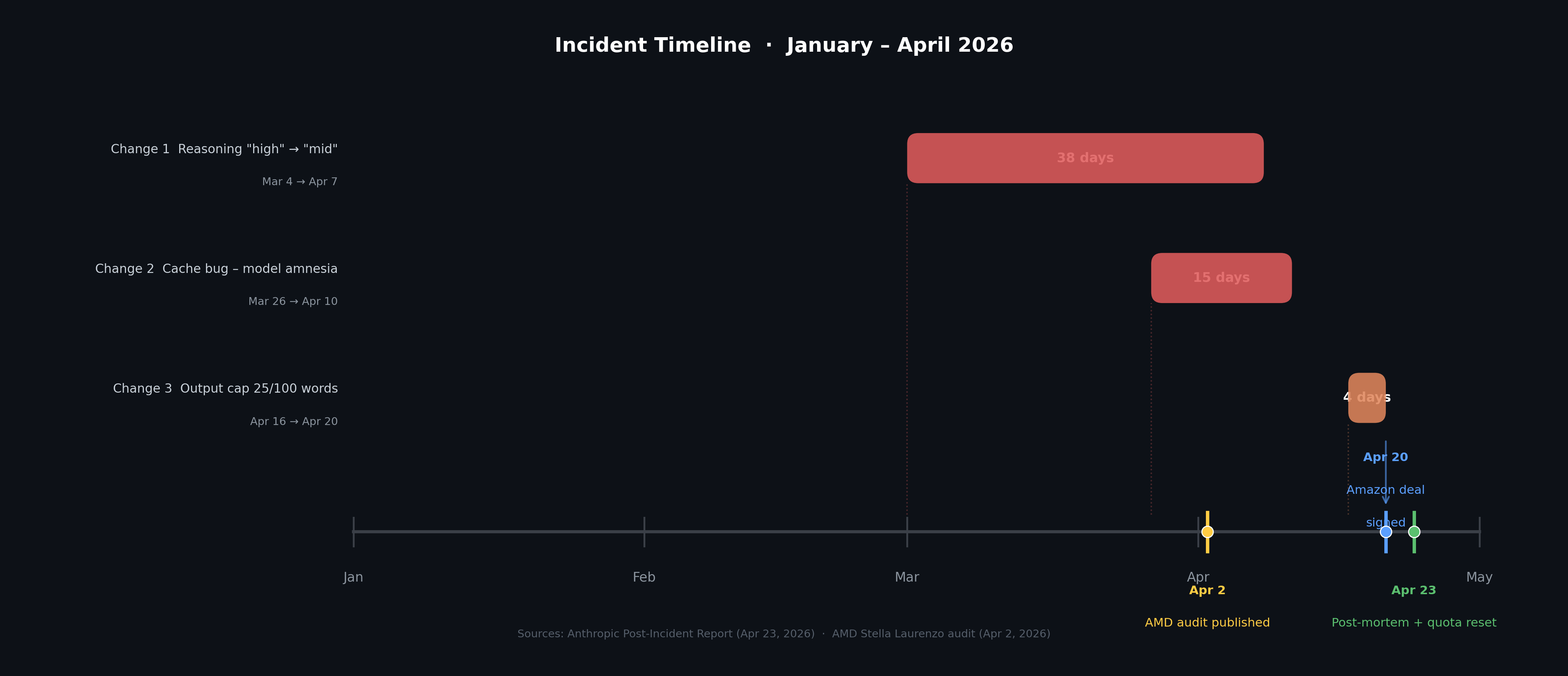
The post-incident report attributed the problems to three independent changes that overlapped—each affecting different products, over different time windows, none catastrophic in isolation, but collectively giving users the sense that everything had broken at once.
Change 1, March 4: The default reasoning intensity was quietly downgraded from “high” to “medium,” with no announcement. The stated rationale: the “high” setting occasionally caused interface freezes and runaway token latency. Shallower reasoning followed, with measurable quality drops on complex tasks. The change was rolled back 33 days later, on April 7.
Change 2, March 26: The engineering team attempted to optimize caching. The design: after a session had been idle for more than an hour, flush old reasoning records and send fewer tokens on resumption—a cost-reduction measure. A bug caused the flush to happen not just after idle periods, but on every single turn. The model was discarding its own reasoning trace after every reply, effectively going amnesiac on the next turn. Fixed 15 days later.
Change 3, April 16: Output constraints were added to the system prompt: a maximum of 25 words between tool calls, and a maximum of 100 words in final replies. The stated rationale was to suppress verbosity in a new model’s output. The result: truncated code, incomplete responses, and a 3% drop in programming quality benchmarks. Rolled back 4 days later.
Official characterization: three independent engineering errors, each with a plausible motivation, but with insufficient assessment of negative impact.
II. Three Threads That Don’t Quite Add Up
Fix Speed vs. Difficulty: The Math Doesn’t Work
Reasoning intensity downgrade (March 4): Flip a parameter—could be rolled back in minutes. Took 33 days.
Cache bug (March 26): Required locating the bug in code and running tests—genuine engineering legwork. Took 15 days.
Output length cap (April 16): Change a config parameter—equally trivial. Took 4 days.
Changes 1 and 3 were technically equivalent in difficulty, yet their fix times differed by nearly 30 days. More tellingly: Stella Laurenzo’s audit data was public as of April 2, giving the outside world quantitative evidence—and yet Change 1 still wasn’t rolled back until five days later. Change 3 was rolled back on April 20—the same day Amazon’s compute capacity expansion deal was signed.
The Two Most Compute-Efficient Changes Took the Longest to Fix
The objective impact of each change on compute consumption:
Reasoning intensity downgrade: Shallower thinking means less computation per request; the same compute budget can handle more concurrent users.
Output length cap: Output generation is the most compute-intensive phase of inference. Capping it at 25/100 words is the single most effective lever for cutting costs immediately.
Cache bug: Actually increased consumption—the model recomputed context from scratch every turn. This one fits the “pure engineering error” characterization best.
If all three were truly independent accidents, the direction of their impact on compute should be random. Instead, the two changes that happened to reduce compute were the slowest to fix. The one that increased compute was fixed on a normal schedule.
The Timing of the Admission Is Too Precise to Dismiss
April 20: Anthropic and Amazon sign a compute capacity expansion agreement; a new tranche of Trainium2 capacity begins coming online in Q2.
April 23: Post-incident report published. Anthropic formally acknowledges the three issues and resets all subscriber quotas. Three days apart.
In the weeks prior, despite sustained user complaints and AMD’s quantitative audit, Anthropic had not issued a formal acknowledgment. Competitive pressure (GPT-5.5 launching the same day) may also have helped trigger the admission—both explanations can coexist. But either way, the timing doesn’t look like coincidence.
The Counter-Argument Is Also Reasonable
A 33-day rollback could simply reflect engineering prioritization—multiple changes stacked on top of each other produce ambiguous symptoms, and bugs that only reproduce in specific session states are genuinely difficult to isolate internally. The compute hypothesis presented here is an interpretive frame, not the only possible answer.
III. How Tight Was the Compute?
Claude Code Is a Compute Black Hole
Ordinary chat is a request-response loop—one exchange, done. Claude Code on a programming task works entirely differently: a single request can trigger dozens or hundreds of tool calls—reading files, analyzing dependencies, writing code, running tests, reading error output, revising—each one an independent inference request carrying an ever-growing context. Net effect: a heavy Claude Code user consumes compute comparable to hundreds or even thousands of regular chat users.
Anthropic’s ARR grew from $1 billion to $30 billion in 15 months—a 30x increase. But compute demand almost certainly grew far more, because the fastest-growing segment was heavy enterprise Claude Code users, not casual chat users. Enterprise customers spending more than $1 million per year doubled from 500 to 1,000 in two months; these customers run automated programming pipelines, and each one consumes compute at a scale no regular user can approach.
Anthropic’s Compute Footprint: A ~1 GW Estimate
The Project Rainier cluster, built jointly by Anthropic and Amazon, is confirmed by both companies’ public announcements to run more than one million Trainium2 chips—making it one of the largest AI inference clusters in the world.
A rough back-of-envelope estimate: each Trainium2 chip has a TDP of roughly 700 watts, putting the theoretical power draw of one million chips at about 700 MW. With cooling, networking, and datacenter overhead (a PUE factor of roughly 1.3–1.5x), total installed capacity comes in around 1 GW—equivalent to the electricity consumption of a mid-sized city, or roughly one million dedicated AI chips running at full load simultaneously.
Actual inference-available capacity is less than the installed total: model training runs overnight, maintenance windows consume a share. Realistically schedulable inference capacity is probably 60–80% of the total, or roughly 600–800 MW. This analysis uses “~1 GW” as a ballpark figure.
This figure is corroborated by the expansion timeline: the April 20 Amazon deal explicitly states that Trainium2 and Trainium3 capacity will add “close to 1 GW” before year-end 2026. In other words, the new contract will roughly double inference capacity by late this year—and the incident happened in the gap before that capacity arrived.
To be clear: chip TDP, full-system power draw, the training/inference split, and actual utilization rates are not fully transparent figures. This is an order-of-magnitude estimate, not a precise accounting. But the direction is clear: Anthropic’s inference compute was running at high utilization during this incident, with little slack.
Architecture: Why There Was No Backup
There’s a common misconception that Anthropic runs independent compute pools on AWS, Microsoft Azure, and Google Cloud, able to cross-cover in a pinch. That’s not quite how it works.
Azure-hosted Claude access, based on Anthropic’s public documentation, has the model running on Anthropic’s own infrastructure—Azure functions more as a procurement and distribution channel than an independent compute pool. The genuinely independent leg is Google Cloud, running on Google’s own TPUs—but that capacity has historically been directed at Google Cloud enterprise customers, not shared with direct subscribers.
The practical implication: during the incident, the vast majority of users—whether subscribing directly, going through AWS, or going through Azure—were drawing from the same pool. There was no failover.
IV. The Capital Markets Have Already Weighed In
In the days surrounding the post-incident report, two very large deals closed.
April 20: Amazon committed up to $25 billion in additional investment; Anthropic committed to spending more than $100 billion on AWS over 10 years, in exchange for up to 5 GW of compute capacity—several times the size of the current cluster, with roughly 1 GW arriving before year-end.
April 24: Google announced an investment of up to $40 billion (with a first tranche of $10 billion landing immediately) and committed another 5 GW of Google TPU capacity, expected online from 2027.
Together, the two deals give Anthropic a medium-term compute reserve of up to 10 GW—an order of magnitude more than today. As of this writing, Bloomberg and the Financial Times report that Anthropic is in talks for a new funding round at a rumored valuation approaching $900 billion, with a raise of up to $50 billion. Reports indicate existing investors’ subscription requests were oversubscribed before the formal process even launched. The market’s characterization of this company has shifted from “AI company” to “AI infrastructure company.”
One investor close to the negotiations put it plainly:
“Anthropic has resolved the biggest bottleneck and potential source of weakness, which is compute.”
— Investor with knowledge of the matter, quoted in Bloomberg
That quote doesn’t prove the incident was caused by compute scarcity. But it makes clear that in the eyes of the people who know Anthropic best, compute was the most fragile element of the company’s foundation. The incident, the capacity deals, and the funding round all converged in the same month. That’s hard to call coincidence.
V. After the Fixes: A Hypothesis Worth Watching
The three changes were “rolled back”—but it’s worth asking: did Claude actually return to its January 2026 state?
Many heavy users report that performance improved from the peak of the incident, but hasn’t quite recovered to where it was at the start of the year.
Here’s a hypothesis that holds together internally: what’s called a “fix” may in practice be finding a new equilibrium that users can tolerate without additional compute—not a genuine restoration to the prior state. Reasoning intensity defaults were reset to “high,” but not higher—and the model’s best performance in January often reflected tasks running at even higher effective intensity. “Restored to high” is not the same as “restored to then.”
A few details fit: after the fixes, Anthropic quietly tested removing Claude Code from the Pro plan, and began moving toward consumption-based pricing that nudges heavy users toward more expensive tiers. These moves look more like continued demand management than a company that suddenly has headroom to spare. AWS’s new capacity starts arriving in Q2, but “starts arriving” is not “arrives at scale”—until that capacity is fully online, some degree of implicit constraint is likely still in place.
This hypothesis can’t be proven, but it can be tested by observation. If it’s right, the real recovery point should come when new compute comes fully online at year-end. That’s a good moment to run comparable tasks and see whether the numbers—and the feel—have meaningfully changed.
Readers with longitudinal usage data are welcome to revisit this then.
Closing
Even if you accept Anthropic’s engineering explanation entirely, one thing is certain:
Users absorbed a degradation in service quality without being told. Subscription fees kept flowing; the experience quietly declined; complaints went largely unaddressed—until the supply-demand picture improved enough for Anthropic to issue a post-mortem.
This isn’t uniquely Anthropic’s problem. It points to a structural tension in the AI agent era: an AI company’s revenue can scale at software speed; the physical infrastructure underneath it cannot. When a gap opens between the revenue curve and the compute curve, user experience is the first casualty.
Compute is not a cloud. It is silicon, server racks, power, and things that take time to build. If this incident has a lasting value, it may be in making that visible.