

The Map That Pharma Didn’t Draw: Reading NVIDIA’s investment portfolio as a field guide to AI in drug discovery

March 2026 · AI × Life Sciences · Investment Lens
On January 12, 2026, Jensen Huang took the stage at the J.P. Morgan Healthcare Conference and said something that deserves more than a passing read:
“AI is transforming every industry, and its most profound impact will be in life sciences.”
He wasn’t speaking in the abstract. He was announcing a joint AI lab with Eli Lilly — up to $1 billion over five years, scientists from both companies working side by side in the Bay Area.
This piece isn’t about NVIDIA. It’s about whether what he said is actually happening — where, how, and what it means for investors.
NVIDIA’s portfolio in life sciences turns out to be a surprisingly useful lens. Every investment the company has made in this space over the past three years lands on a specific node in the drug discovery chain. Connect them, and you get a map — not one drawn by pharma, not one drawn by academia, but one drawn by a company that makes money when AI computation scales.
That’s a different kind of map. Let’s follow it.
I. Why Now?
Start with a number that has defined — and frustrated — the pharmaceutical industry for decades: developing a new drug costs roughly $2.6 billion and takes about twelve years, with a success rate below 10%. That’s not an efficiency problem. It’s an epistemological one.
Biology, especially human disease biology, is a high-dimensional complex system. Proteins fold in ways we’re still learning to predict. Drug candidates that kill cancer cells in a dish often do nothing — or worse — in a human body. The gap between laboratory signal and clinical truth is enormous, and crossing it has always required brute-force trial and error.
Three things changed in the past five years, and they changed at roughly the same time.
Data crossed a threshold. High-throughput sequencing made genomic data exponentially cheaper to generate. Single-cell RNA sequencing gave researchers cellular-resolution views of biology that simply didn’t exist a decade ago. Companies like Recursion began running over two million wet-lab experiments per week, accumulating biological datasets at a scale previously unimaginable in pharma.
A generational algorithm breakthrough arrived. AlphaFold2, released by DeepMind in 2020, solved protein structure prediction at experimental accuracy — a problem that had stumped structural biology for fifty years. More important than the result was what it proved: that deep learning could brute-force problems in biology that human reasoning had failed to crack. Diffusion models, graph neural networks, large language models — tools built for images and text — began being systematically adapted for molecular design.
The compute infrastructure became economical. Training a protein language model that would have cost millions of dollars and months of compute time in 2018 now runs in days at a fraction of the cost. This is the direct reason NVIDIA entered this story — though it’s far from the whole story.
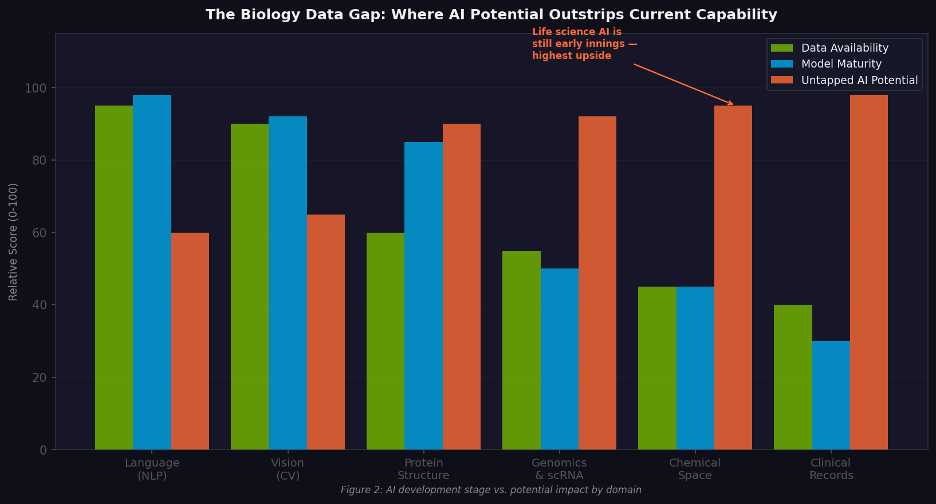
Figure 1. AI development maturity vs. potential impact by domain. Life sciences sits at the bottom-left: least mature, highest upside.
📌 Investor framing When data accumulation, compute economics, and algorithm capability converge simultaneously, history suggests you get a cohort of generational companies. The last time this happened — around 2012, when deep learning first demonstrated dominance in image recognition — it produced Waymo, DeepMind, and the foundation models that followed. The current convergence is centered on life sciences.
II. What NVIDIA Actually Is in This Story
Before walking the map, it’s worth being precise about NVIDIA’s role — because it’s easy to overstate.
NVIDIA does not discover drugs. It does not run clinical trials. The actual biological breakthroughs happen in labs run by scientists who have spent careers understanding disease. NVIDIA’s contribution is three things:
• Compute infrastructure: the GPU clusters that make training large biological foundation models physically possible
• Software stack: a platform that standardizes how that compute gets used for life science AI
• Strategic capital: investments through NVentures that tie financial returns to compute adoption
Two terms worth defining for readers who may not follow NVIDIA closely:
BioNeMo is NVIDIA’s life sciences AI development platform, launched in 2022. It’s not a single model — it’s a toolkit: pretrained foundation models for proteins, RNA, and small molecules; GPU-accelerated chemistry libraries; deployment infrastructure that lets different models talk to each other. Think of it as middleware for biological AI. A drug company or biotech doesn’t need to build AI infrastructure from scratch — it builds on top of BioNeMo.
NVentures is NVIDIA’s venture arm, launched the same year and led by Sid Siddeek, formerly of SoftBank. Unlike a traditional VC, NVentures isn’t primarily optimizing for financial returns. It’s looking for companies whose scaling trajectory creates natural, structural demand for NVIDIA compute. The companies NVentures funds tend to become NVIDIA’s largest compute customers.
Put those together and NVIDIA’s role becomes clear: it’s a router. Capital, compute, software, and partnership network all run through it. But a router doesn’t generate the signal — it amplifies and directs it. The biological innovation is happening elsewhere.
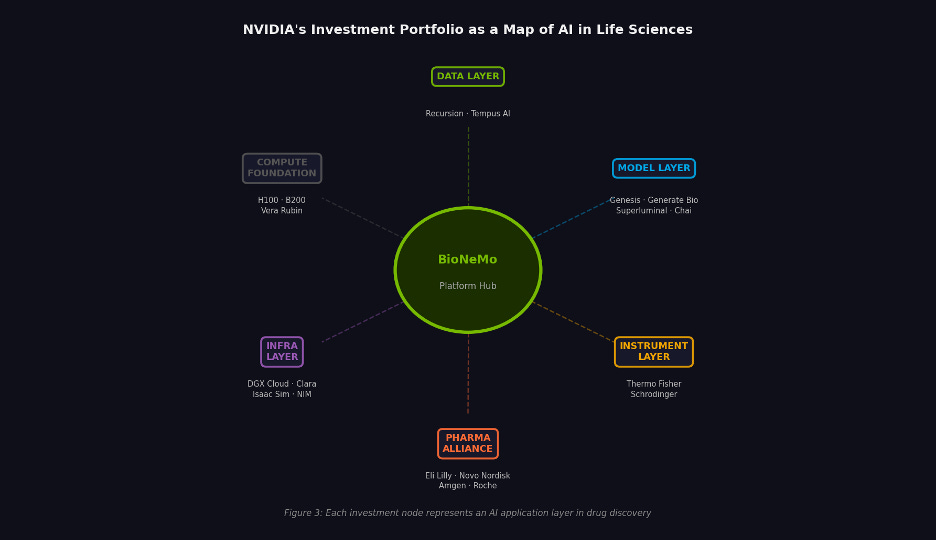
Figure 2. NVIDIA’s life sciences portfolio mapped by layer. Each node represents a distinct application of AI in drug development.
III. The Data Layer: Why Biological Data Is Different
Every AI story begins with data. But the data moat in life sciences works differently from the one in consumer internet — and the difference matters enormously for investors.
In internet businesses, more data generally means better pattern recognition. User clicks accumulate, models improve, recommendations get sharper. The moat is built on volume and coverage.
In drug discovery, three stricter conditions apply:
First, data generation must be a closed loop. A compound gets tested, produces an experimental result, that result informs the design of the next compound, and the new experiment feeds back into the model. If this cycle is controlled and reproducible — if every experiment makes the AI’s next prediction slightly better — you have a flywheel. If data comes from scattered, heterogeneous sources, you have an archive, not a moat.
Second, label quality matters more than volume. A user click is a clean label. In drug development, “active in a cell assay” and “effective in a human patient” are separated by years of clinical trials and a brutal attrition rate. The depth and clinical relevance of labels determines what a model can actually predict — and where its predictions break down.
Third, data must connect to decisions. Data locked in academic papers has zero commercial value. Data that’s embedded in research workflows — that actively shapes what scientists do next — is the asset.
Recursion: The Experiment Factory
Recursion’s model, stated plainly: industrialize the production of machine-learnable biological data.
The company runs over two million cellular experiments per week. Each experiment is imaged under high-content microscopy; AI extracts phenotypic features from those images — how does a cell’s morphology change when a particular gene is knocked out? These features are high-dimensional and invisible to the human eye, but they constitute a training signal for predicting drug biology.
Accumulated over years, this is now 50 petabytes of biological and chemical data — more than any pharmaceutical company has assembled. More important than the scale is the architecture: the data generation system is itself the AI’s feedback loop. Each experimental result iterates the model’s next prediction. That’s what makes it a flywheel rather than an archive.
NVIDIA didn’t just take an equity stake — it co-built BioHive-2, a DGX SuperPOD running 504 H100 Tensor Core GPUs. When it came online in May 2024, it ranked #35 on the TOP500 list of the world’s most powerful supercomputers, across all industries. A drug company’s internal supercomputer in the global top 50 is not a normal state of affairs.
“With AI in the loop today, we can get 80% of the value with 40% of the wet lab work. And that ratio will improve going forward.” — Ben Mabey, CTO, Recursion
NVIDIA subsequently exited its equity position. The platform relationship continues. This is actually the more revealing detail: the equity was an entry point; the compute binding is the durable position.
Tempus AI: Clinical Labels at Scale
Recursion’s data comes from the lab. Tempus’s comes from patients.
The company has accumulated over 38 million multimodal clinical records — genomic sequences, pathology images, electronic health records, treatment regimens and outcomes. Its business model: provide genomic testing to hospitals in exchange for data licensing rights, then monetize that data through licensing agreements with pharmaceutical companies.
The strategic value isn’t the volume. It’s that Tempus’s data carries real-world clinical labels — treatment decisions and patient outcomes — that most AI drug discovery companies don’t have access to. A model trained on Tempus data can predict patient response, not just in-vitro activity. That distinction is the entire gap between “promising compound” and “approved drug.”
📌 The data moat thesis In life sciences, durable data advantages come from three sources: closed experimental loops (Recursion), real-world clinical labels (Tempus), and proprietary datasets that compound over time through active use in research decisions. Volume alone — data scraped from public sources, curated from literature — is not a moat. It’s table stakes.
IV. The Model Layer: Designing Molecules That Have Never Existed
This is where the technology gets most interesting — and where investor expectations are most prone to getting ahead of the evidence.
Traditional hit discovery in drug development works like a massive search problem: take a library of a few million compounds, screen them one by one against a target protein, identify which ones bind, and optimize from there. High-throughput screening is slow, expensive, and fundamentally backward-looking — you can only find molecules that already exist.
Generative AI changes the direction of the problem. Instead of searching an existing library, you generate candidates that have never been synthesized. Given a target protein and a desired set of molecular properties, the model outputs novel chemical structures. The mechanics are the same as image generation — latent space navigation, diffusion, conditional sampling — applied to molecular geometry instead of pixels.
Genesis Therapeutics: Physics-Constrained Molecular Design
Genesis’s platform, GEMS (Genesis Exploration of Molecular Space), sits at the intersection of physics and deep learning. Its core architecture relies on equivariant neural networks — a class of models that naturally handles 3D geometric data, preserving the rotational and translational symmetries of molecular structures. This matters because a drug molecule’s binding behavior is determined by its three-dimensional shape, not just its chemical formula.
NVentures participated in Genesis’s $200 million Series B in 2023 and made an additional equity investment in November 2024. The second investment came with a technical collaboration: NVIDIA helping Genesis optimize GPU execution for equivariant networks; Genesis’s work feeding back into BioNeMo’s physical AI capabilities. This co-development structure — money plus engineering collaboration — is what distinguishes NVentures from a financial investor.
“NVIDIA leads in the AI stack — hardware and the software layers above it. Genesis has been pioneering molecular AI as an intellectual area. The synergies are very clear.” — Evan Feinberg, CEO, Genesis Therapeutics
Generate:Biomedicines: Proteins as Programmable Matter
If Genesis works on small molecules, Generate tackles the harder problem: designing protein therapeutics from scratch.
Biologics — antibodies, enzymes, cytokines — are generally more precise and less toxic than small molecules, but designing them has historically required years of iterative trial and error. Generate’s thesis is that generative AI can make protein design systematic: specify the function you want, receive candidate sequences, build and test.
Their pipeline now spans 17 programs across oncology, immunology, and infectious disease. NVentures joined Amgen and a group of institutional investors in a $273 million Series C in 2023 — one of the largest single rounds in biotech that year. The Flagship Pioneering provenance (the firm that incubated Moderna) is notable: Flagship has a track record of building platform companies that eventually become infrastructure for the industry.
Superluminal Medicines: The GPCR Problem
About 34% of all FDA-approved drugs work through G protein-coupled receptors (GPCRs). They are also among the most computationally difficult targets to model — embedded in the lipid bilayer of cell membranes, highly dynamic in structure, resistant to the standard structural prediction methods that work well for soluble proteins.
Superluminal focuses exclusively on generative design for GPCRs. NVentures participated in both its seed round and its $120 million Series A. Eli Lilly co-invested in that same Series A — months before Lilly and NVIDIA announced their $1 billion co-innovation lab. Shared cap tables often precede formal strategic partnerships.

Figure 3. AI intervention points across the drug discovery pipeline, with representative companies at each stage.
A tension worth naming now
Before leaving the model layer, one question deserves a direct answer: if foundation models keep getting open-sourced, how long do proprietary model advantages last?
AlphaFold2 is open-source. Boltz-2 — trained on Recursion’s BioHive-2 by MIT researchers, released in late 2025 — is open-source, achieves near-physics-simulation accuracy for protein structure and binding affinity prediction, and runs in about 20 seconds on a single A100. ESM-2 (Meta’s protein language model) is open-source.
The implication is uncomfortable but important: a company whose core differentiation is “our model is better than the open-source baseline” has a moat with a short half-life — probably 12 to 18 months at current rates of progress.
Where value actually accrues as the base model layer commoditizes is the subject of the next section.
V. The Value Stack: Where Does the Moat Go When Models Go Free?

Figure 4. Value capture hierarchy. As base model capability commoditizes, durable advantage shifts to the layers above it.
The base layer — foundation model capability — is rapidly commoditizing. This is not a prediction; it’s already happening. AlphaFold, Boltz-2, and ESM-2 are available to any researcher with a GPU. The quality is high enough to cover most baseline prediction needs.
The layer above that is workflow and tool embedding. The moat here is switching cost, not technical superiority. Once Schrödinger’s FEP+ is adopted by a computational chemistry team, the team’s entire workflow, historical data, and internal protocols are built around it. Replacing it costs two or more years of rebuilding. When NVIDIA embeds DGX infrastructure into Schrödinger — and by extension into every research program running on Schrödinger — it’s reinforcing a software lock-in with hardware dependency.
Above that: proprietary data plus experimental closed loops. This is the layer hardest to replicate, and the one where capital compounded over time creates the most defensible advantage. Recursion’s 50PB dataset isn’t just large — it’s a live system. Every experiment makes the AI’s next prediction marginally better. This kind of compounding takes years of capital deployment and operational discipline to build. It cannot be shortcut by buying a better GPU cluster.
At the top: clinical assets and pipeline. The highest barrier, the lowest liquidity. A Phase II asset can be worth a billion dollars — but you’ll wait seven years to find out if it works.
The practical investor question: which layer are you buying, and is that layer’s moat widening or eroding? Many current valuations in this space conflate layers — pricing companies as if they have clinical asset depth when their actual differentiation is at the tool layer, or vice versa.
VI. The Tool Layer: Embedding AI in the Lab’s Daily Work
Models and data only matter if they change what scientists actually do on a given Tuesday. That’s a workflow problem, not a technology problem.
Researchers in drug discovery work with specific instruments, specific software, specific data formats. Getting AI into their process means embedding it in tools they already use — not asking them to adopt new platforms.
Schrödinger: The Standard That Became Infrastructure
Schrödinger’s FEP+ software occupies roughly the position in computational chemistry that Excel occupies in finance: not always the best tool for every specific task, but so deeply embedded in how the field trains people and structures workflows that replacement is practically unthinkable.
NVIDIA’s integration with Schrödinger means that when thousands of computational chemists run molecular docking simulations, the compute runs on DGX infrastructure and BioNeMo tooling sits in the same stack. NVIDIA’s most effective form of market penetration in life sciences isn’t product launches — it’s being embedded in products that are already trusted.
Thermo Fisher: The Instrument Network
Thermo Fisher’s mass spectrometers, flow cytometers, and high-content imaging systems are present in effectively every major pharmaceutical company and research institution on the planet.
The NVIDIA-Thermo Fisher collaboration targets autonomous data interpretation: an instrument completes a run, AI immediately analyzes the output, integrates it with other experimental data and model predictions, and recommends next steps. No waiting for a scientist to process results the next morning.
The strategic significance extends beyond the technology: Thermo Fisher’s customer network reaches thousands of downstream organizations. Every instrument that connects to BioNeMo is a new distribution node. This kind of channel leverage is more valuable than NVIDIA going company-by-company to negotiate partnerships.
VII. The Strategic Layer: When Big Pharma Commits
The data layer, model layer, and tool layer are still largely in validation mode. Most of the companies are pre-revenue or early-stage. The real commitment signal comes from how established pharmaceutical companies are allocating capital.
Big pharma sets industry benchmarks. When Lilly publicly commits to a specific infrastructure stack, every other pharma company’s CTO has to answer the same question: why aren’t we doing this?
Eli Lilly: The $1 Billion Bet
The January 2026 announcement was unusually specific for a pre-commercial AI collaboration: up to $1 billion over five years, a physical co-location in South San Francisco, Lilly biologists working alongside NVIDIA engineers, and a stated scope covering the entire R&D chain from target identification to manufacturing.
The detail that matters most: Lilly had already built the most powerful internal AI factory in biopharma — a DGX SuperPOD — before agreeing to this lab. This is not a company outsourcing AI capability because it lacks the resources to build internally. It’s a company that has built internal capability and concluded that joint development accelerates faster than independent development. The distinction between outsourcing and co-building is significant.
“Combining our volumes of data and scientific knowledge with NVIDIA’s computational power and model-building expertise could reinvent drug discovery as we know it.” — David Ricks, CEO, Eli Lilly, January 2026
Novo Nordisk: The Sovereign AI Angle
In June 2025, NVIDIA and Novo Nordisk announced a collaboration tied to the Gefion supercomputer — Denmark’s national AI infrastructure, operated by DCAI. Novo Nordisk will use BioNeMo and related NVIDIA tooling to build single-cell models predicting drug response, design molecules with drug-like properties, and train biomedical LLMs on its scientific literature corpus.
The broader significance: this is a proof-of-concept for national AI infrastructure serving domestic pharmaceutical champions. If it works, expect variations of this model to appear in other countries — Germany (Bayer, BioNTech), Switzerland (Roche, Novartis), Japan (Takeda, Astellas). Sovereign AI as pharma infrastructure is an underappreciated structural trend.
VIII. Three Investment Theses — Pick One Before You Pick a Company
The most common analytical mistake in this sector isn’t picking the wrong company. It’s applying the wrong valuation framework to the right company. There are three distinct investment theses in AI drug discovery. Each has different beneficiaries, different valuation logic, and a different risk profile.

Figure 5. Three investment theses, three valuation frameworks. Conflating them is the sector’s most common analytical error.
Thesis One: Compute Consumption Growth
The core bet: AI drug discovery will drive exponential GPU demand, making compute providers the primary beneficiaries regardless of which drug companies succeed.
There’s real logic here. Training a protein language model on a proprietary dataset requires hundreds of GPUs running for weeks. If hundreds of companies are doing this simultaneously, aggregate compute demand is substantial. Inference at scale adds more.
The internal tension: AI efficiency gains compress cost-per-discovery. Better models run fewer failed experiments; better inference engines use less compute per query. If AI genuinely improves drug discovery economics, the reduction in wasted experiments may partially offset compute demand growth. The relationship between AI adoption and GPU demand is not obviously linear.
Primary beneficiaries: NVIDIA, cloud hyperscalers, DGX infrastructure operators. Valuation logic: hardware and cloud revenue multiples. Verification timeline: 1–3 years (revenue visible).
Thesis Two: Clinical Success Rate Improvement
The most ambitious thesis: AI meaningfully increases the probability of clinical success, raising the industry’s approximate 10% drug approval rate toward 20–30%.
If true, the value creation is enormous. Every percentage point of clinical success rate improvement is worth billions across the industry. The companies that own AI-discovered drug pipelines — Genesis, Generate, Recursion — would be repriced on biotech NPV metrics.
The problem is verification: this thesis requires ten years and multiple Phase III readouts to prove. There are currently 173 AI-assisted drug programs in clinical trials globally; approved drugs from that cohort are still rare. The evidence is accumulating, but slowly.
This means current valuations for companies in this category are priced on the probability of a future proof point, not an existing one. That’s a legitimate investment, but it’s a faith-based valuation until the clinical data arrives. Understand what you’re underwriting.
Thesis Three: R&D Workflow Softwarization
The most tractable near-term thesis: AI converts portions of drug discovery into software — recurring, scalable, subscription-based.
Drug discovery has historically been bespoke and service-oriented. If AI makes specific workflows (molecular screening, structural prediction, toxicity assessment) commoditized and deliverable as SaaS, the industry’s cost structure changes and software-style multiples become defensible for the platform companies.
Primary beneficiaries: Schrödinger, Tempus AI, BioNeMo as a SaaS layer. Valuation logic: ARR multiples (10–20x). Verification timeline: 3–5 years of ARR growth.
Key risk: large pharma companies have demonstrated willingness to build internally. As internal AI capability matures, pricing pressure on external SaaS providers increases. Open-source model progress also narrows the differentiation window for tool-layer companies.
Knowing which thesis you’re buying is more important than which company. Many investors use SaaS multiples to value companies whose actual economics are biotech NPV — or wait with biotech patience for companies that should be held to SaaS growth accountability. Both produce wrong conclusions.
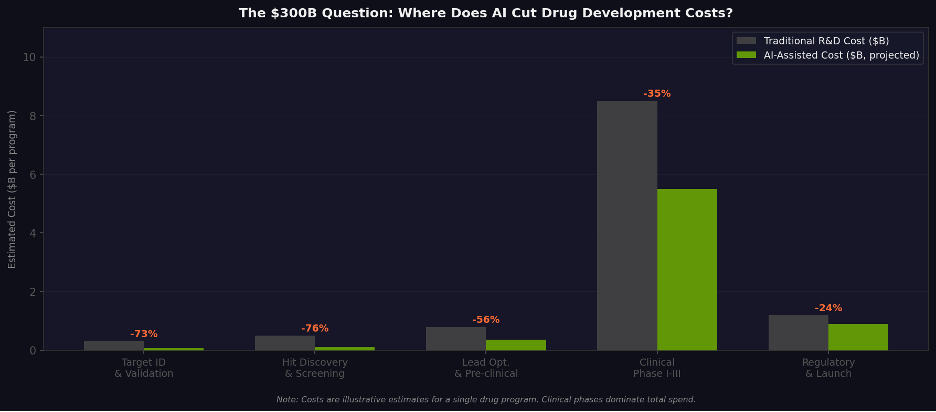
Figure 6. Estimated AI impact on R&D costs by stage. Value concentration in early discovery; clinical phases dominate total spend.
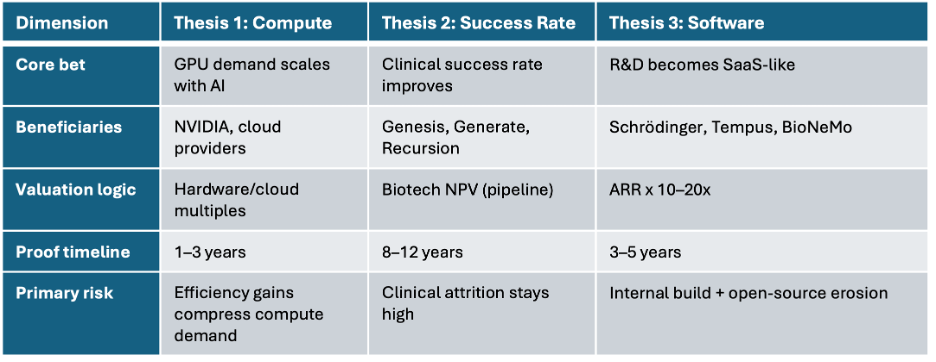
Table 1. Three investment theses compared across key analytical dimensions.
IX. The Risks That Actually Matter
The standard risk disclosures in this space tend to describe symptoms. Here’s an attempt to name the underlying conditions.
The timeline problem is structural, not temporary
The observation that “AI drugs are far from approval” is usually framed as a technology maturity issue. It’s more accurately a structural verification problem: the clinical trial system is the bottleneck, not the AI.
A drug entering Phase I clinical trials is a meaningful milestone. But Phase I success is roughly 60–65% likely; Phase II drops to about 30–40%; Phase III to 55–60% of what enters. Roughly 90% of drug candidates that reach clinical testing don’t get approved. AI can improve the quality of candidates entering the pipeline, but it cannot speed up Phase II or III trials — those are governed by patient accrual rates, regulatory standards, and the biology of disease.
The practical implication: most AI drug discovery companies’ core value propositions will remain unverifiable for five to eight years. For funds with defined return windows, this is a structural problem, not a risk to be managed.
Open-source erosion is asymmetric in its damage
The commoditization of base models damages some companies and actually benefits others — and the split is not random.
Companies whose competitive moat is “better foundation model than the open-source baseline” are in genuine trouble. The baseline is improving faster than proprietary models can maintain distance. A startup whose pitch centers on a novel protein structure prediction model had better have a second act.
Companies whose moat is proprietary data and experimental closed loops are in the opposite position. Open-source base models make proprietary data more valuable, not less — better models extract more signal from the same dataset. Recursion’s 50PB of experimental data becomes more valuable as the models trained on it improve.
The company to worry about is the middle layer: platforms that wrap open-source models in a user-friendly interface and call it a moat. These businesses had a window when ease-of-use was a genuine differentiator. As open-source tooling improves, that window is closing.
Big pharma’s in-house build is a signal, not just a risk
Lilly built a DGX SuperPOD AI factory internally. Then it signed a $1 billion co-innovation agreement with NVIDIA. These aren’t contradictory — they’re sequential. The internal build was the prerequisite for the co-building.
The real risk isn’t pharma building internal capability. It’s that once pharma AI capability matures past a certain threshold, external tool providers face pricing pressure they can’t resist. A pharma company that can plausibly build something itself is a much harder customer than one that can’t. Margins on external AI services will compress as the buyer’s outside option improves.
Most companies in this space are selling a narrative, not a result
This is the one that’s hardest to say out loud, but it’s the most important.
The majority of AI drug discovery companies are currently selling the claim that their platform improves the probability of future success — not the demonstration that it already has. The distinction matters for how you price the asset.
When you buy equity in most companies in this category, you’re pricing a probability uplift claim. There is a meaningful evidence gap between “our platform improves early-stage screening efficiency” and “our platform produces drugs that work in humans.” That gap will eventually close — some of these companies will produce clinical data that validates their platforms. But until it does, current valuations represent a collective bet on a thesis, not a payment for proven results.
That’s not necessarily wrong. It’s just what it is. Pricing it like proven results is.
📌 Portfolio framing Companies with experimental data flywheels and clinical-stage assets (Recursion, Generate Bio pipeline) warrant biotech-style evaluation and patience. Tool-layer companies (Schrödinger, Tempus) should be held to SaaS growth accountability. Compute beneficiaries (NVIDIA) offer non-symmetric exposure to the sector without the clinical binary risk. Mixing these frameworks within a single portfolio position tends to produce analytical confusion.
X. What the Map Actually Shows
AI’s penetration into drug discovery is not a single breakthrough. It’s a multi-layer, multi-speed process.
The data layer is building experimental flywheels that compound over years. The model layer is producing generative capabilities that didn’t exist five years ago — and watching those capabilities commoditize almost in real time. The tool layer is quietly embedding AI into the daily instruments of laboratory science. The strategic layer is seeing the largest pharmaceutical companies make irreversible infrastructure commitments.
NVIDIA’s role in this, as I’ve tried to frame throughout, is that of a router — capital, compute, and software converging at a single node, then distributed outward. That’s a significant structural position. It’s also a position that doesn’t require NVIDIA to be right about which drugs work. It just requires AI computation in biology to keep scaling, which is the less speculative part of this entire story.
The harder bets are on the companies doing the biology. The data flywheels need clinical validation. The generative models need Phase II and Phase III readouts. The tools need sustained adoption as internal pharma AI capability grows. None of these are certain.
Jensen Huang’s claim — that AI’s most profound impact will be in life sciences — is, as a long-term thesis, probably right. The question for investors isn’t whether the destination exists. It’s which vehicles actually get there, at what speed, and whether the entry price already reflects the journey.
Disclaimer: This article is for informational and research purposes only and does not constitute investment advice. All figures current as of March 2026. Market capitalizations and funding amounts are publicly disclosed or estimated.
Sources: NVIDIA Investor Relations, NVIDIA Newsroom, company press releases, SEC filings, and published industry research.
Interesting take. The biggest shift in pharma isn’t just AI tools, but how companies rethink data, decisions, and strategy around them.