

The Most Dangerous LLM Hallucination Nobody Talks About: Time

A personal encounter, 50 runs per model, and what it means for anyone using AI to track the news
I use AI to keep up with the news. Specifically, I need a fast read on what happened in AI and tech in the past 24 hours — ideally before my first meeting of the day.
So I built a workflow around it. Carefully worded prompts, strict instructions to use only real-time sources, mandatory timestamps for every claim. The output looked good. Clean, confident, well-structured — the kind of briefing you’d actually forward to a colleague.
Then one morning I happened to fact-check one of the items. The event it described as “announced today” had happened six months earlier.
The model hadn’t invented anything. The event was real. The details were accurate. It had simply picked up a genuine story from six months ago, dressed it in present-tense language, and served it as breaking news — and I, the person who wrote the prompt, didn’t catch it on first read.
This wasn’t a one-off glitch. It was systematic. And the gap between models turned out to be much larger than I expected.
That realization prompted a structured test: the same prompt, five leading models, 50 independent runs each, every output manually verified for temporal accuracy. This piece is the full write-up — the numbers, the patterns, and the underlying mechanics.
· · ·
The Test
The task was consistent across all runs: summarize significant events from the past 24 hours in AI, major tech companies, and the macro economy. The five models tested were ChatGPT (Browse enabled), Gemini Standard, Gemini Deep Research, Claude (web tools enabled), and Grok.
Each model ran 50 times independently. Every factual claim in every output was manually checked. The single criterion for failure: was something presented as having happened within the last 24 hours when it actually hadn’t?
The prompt used throughout:
Prompt Used
You are a real-time intelligence analyst. Your task is to summarize
ONLY events that have occurred in the past 24 hours.
STRICT RULES:
1. You MUST search for and cite real-time sources published within
the last 24 hours. Do not rely on training data.
2. For every event you mention, you MUST include:
- The exact source name
- The publication timestamp
3. If you cannot find a verified source from the past 24 hours for
an event, you MUST explicitly state: “I cannot confirm this is
within the 24-hour window” — do NOT include it as current news.
4. Do NOT use phrases like “recently”, “this week”, or “earlier”
as substitutes for precise timestamps.
5. If no verifiable real-time information is available, say so
directly rather than filling the gap with older content.
Topic areas: AI industry, major tech company events, macro economy.
Length: ~400 words.
· · ·
Results
The table below is the core data. Each model’s failure pattern is distinct — I’ll break them down individually after.
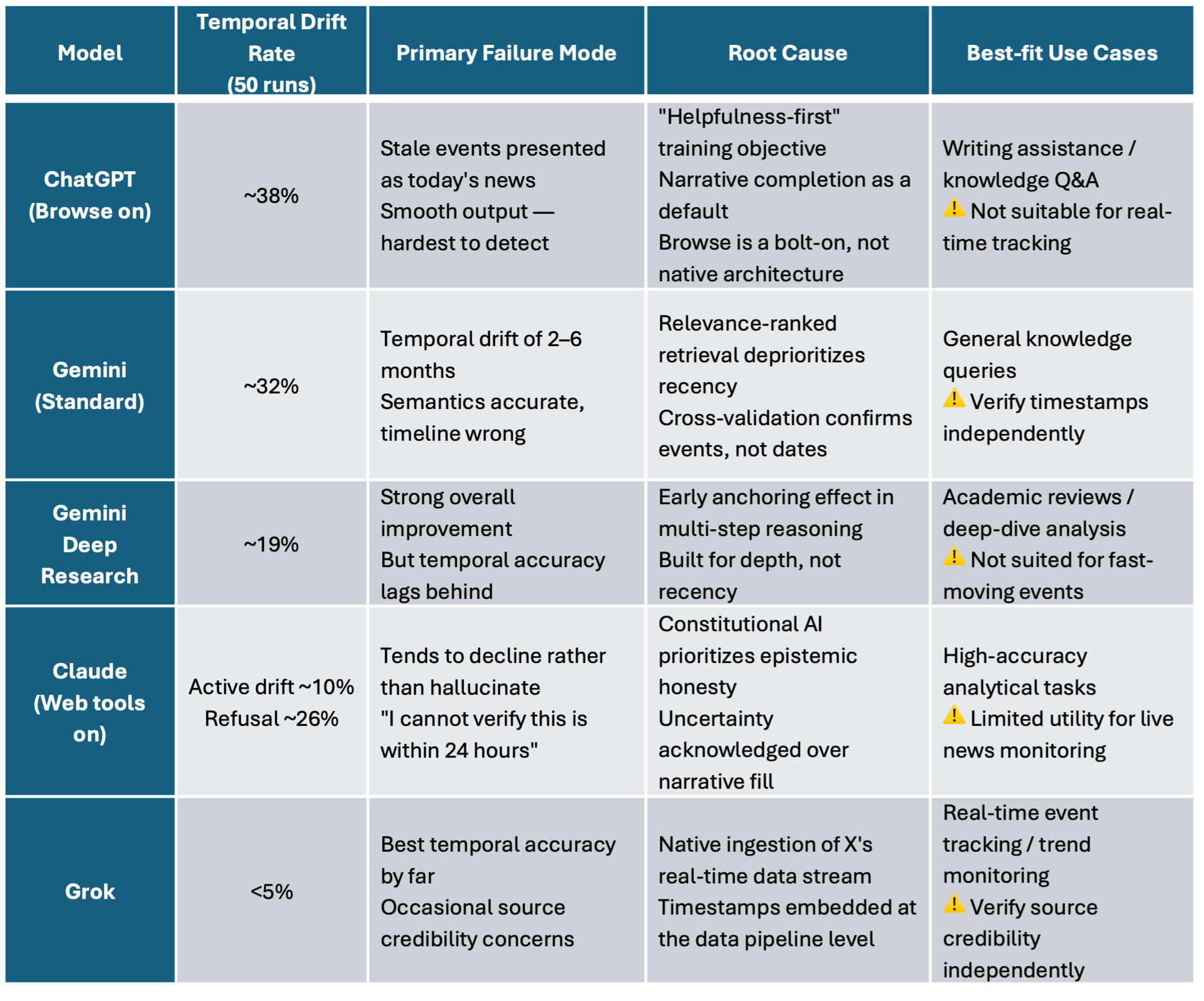
Note: These figures reflect the author’s observational testing under specific conditions and should not be read as standardized hallucination rates. All models iterate continuously; results may shift across versions.
Four patterns stood out.
Pattern 1: Strong prompts can’t fully override training objectives
Even with an explicit instruction to use only sources from the last 24 hours with mandatory timestamps, ChatGPT and standard Gemini still drifted frequently. The issue isn’t prompt clarity — it’s that these models have a deeper internal pull toward using relevant facts they already “know,” regardless of when those facts originated.
Pattern 2: Deep Research improves factual accuracy but not temporal accuracy
Gemini Deep Research was noticeably better at avoiding fabrications. But its improvement on temporal displacement was disproportionately small. That asymmetry isn’t random — there’s a structural explanation (covered in the mechanics section below).
Pattern 3: Claude fails differently — it goes quiet rather than going wrong
Claude’s active temporal drift rate was around 10%, relatively low. But in about 26% of runs, it declined to answer rather than risk presenting unverifiable information as current. That’s the more honest failure mode — but it’s still a failure if you actually need the information.
Pattern 4: Grok has the best temporal accuracy, but a different kind of problem
Grok’s temporal drift rate came in below 5%, the most consistent of any model tested. But in roughly 8% of runs, the output was temporally accurate while being sourced from unverified or clearly opinionated X posts. Getting the date right and getting the facts right are two separate things.
· · ·
Why It Happens: Four Mechanisms
The numbers above aren’t noise. Each pattern has a traceable cause.
1. The helpfulness trap
Every major LLM faces a fundamental training tension: when a model is uncertain about the recency of a piece of information, should it say so — or should it produce a complete, useful-sounding answer anyway? Models optimized primarily for user satisfaction tend to resolve that tension toward completion. When a user signals they want “the latest news,” the model experiences pressure to deliver something that feels current, even if that means filling gaps with older material. RLHF reinforces this: human raters tend to prefer confident, well-formed responses over hedged or incomplete ones, which inadvertently trains models to paper over temporal uncertainty. Temporal hallucination, in many cases, is helpfulness gone wrong.
2. Native data pipeline vs. retrofitted search
Most models retrieve information via search APIs that rank results primarily by semantic relevance, with recency as a secondary signal. A highly relevant article from six months ago can easily outrank a vague but current one. By the time the model synthesizes its output, the time metadata has often been smoothed away in the interest of narrative flow.
The alternative architecture is a native, high-frequency data stream with timestamps embedded at the ingestion layer — not inferred during generation, but structurally present before the model ever sees the content. This is a pipeline-level difference, not something tunable through prompting or fine-tuning. One important clarification: even a model trained with a strong “truth-seeking” objective would likely still exhibit significant temporal drift if its retrieval layer runs through a standard semantic search ranking. What matters for this specific failure mode is the data pipeline architecture, not the RLHF preference profile.
3. Early anchoring in multi-step reasoning
In agentic or deep research modes, whatever gets retrieved first has an outsized influence on everything that follows. If the initial retrieval surfaces semantically relevant but temporally stale content, that content establishes a frame that subsequent steps tend to conform to rather than contradict — even when later retrievals turn up more current material. The model prioritizes narrative coherence over temporal correction. This explains why Deep Research improves factual quality without proportionally improving temporal accuracy: it’s better at verifying whether things happened, but still anchors to early retrievals when constructing the timeline.
4. Epistemic humility as a design choice
When a model can’t verify the recency of a claim, what does it do by default? Some models are trained to hedge or refuse; others default to confident output. Epistemic humility has to be explicitly trained in — and it comes with a real cost: users sometimes interpret “I’m not sure” as “this model is weak.” In a commercial environment where satisfaction scores drive optimization, the cautious response often loses to the confident one.
· · ·
A Broader Framework: Three Types of Hallucination
It’s worth situating temporal hallucination within the larger taxonomy of LLM failures. Researchers generally distinguish three types:
Factual hallucination: the model invents something that never existed — a person, a statistic, an event. The harm is real, but detection is relatively straightforward: the claim has no basis in reality and can be fact-checked.
Causal hallucination: the model misattributes causation — treating correlation as cause, or reversing the direction of a causal relationship. More insidious in analytical contexts, but usually catchable by a domain expert.
Temporal hallucination: the model takes something that really happened and transplants it into the present, presenting it as current news.
Temporal hallucination is the most dangerous of the three — not because it’s the most common, but because it’s the hardest to catch. The underlying event is real. The details check out. The only thing wrong is when.
A fabricated statistic tends to trigger skepticism. A real event, accurately described, presented with present-tense confidence — almost nobody checks the original date. That’s what makes temporal hallucination so corrosive in high-stakes contexts: competitive intelligence, financial event tracking, policy monitoring. The difference between “announced today” and “announced last quarter” can change an entire strategic read.

· · ·
Model by Model
ChatGPT — The most convincing failure
The highest temporal drift rate in the test, and by far the hardest to catch. ChatGPT’s outputs are polished, confident, and detailed — which is exactly why they’re dangerous. When a summary reads like a real briefing, complete with attributed analyst commentary, the instinct to verify weakens. The root issue is the training objective: “be as helpful as possible” creates strong internal pressure to produce complete-sounding answers when users ask for current information, even when current information isn’t available. Browse is a retrofit, not a native feature, and its time-filtering signal gets diluted in longer reasoning chains.
There’s also a trust-amplification problem. ChatGPT has the largest user base and the highest ambient trust level. A lot of people treat its output as a primary source — copy it into reports, forward it without checking. The actual harm from temporal hallucinations in ChatGPT therefore runs well ahead of what the drift rate alone would suggest.
Gemini Standard — Passive drift, not active fabrication
Gemini’s failure mode is subtler than ChatGPT’s. It’s not that it’s making things up — it’s that its retrieval layer ranks by semantic fit, and a semantically relevant article from five months ago can surface ahead of a less precise current one. The model then absorbs that framing without flagging the date gap. Its cross-referencing approach helps verify whether events occurred; it doesn’t help verify when. Multiple sources confirming a stale story just make it look more credible.
Gemini Deep Research — Depth is the priority, not recency
Deep Research is meaningfully better at avoiding fabrication, and the overall quality of its outputs is higher. But the improvement in temporal accuracy is noticeably smaller than the improvement across other error types — and that gap is structural, not coincidental. The product is designed to optimize for coverage, source diversity, and analytical depth. For literature reviews or industry deep-dives, that’s the right trade-off. For real-time monitoring, early anchoring effects systematically pull the timeline backward, and the architecture doesn’t correct for it.
Claude — Honest to a fault
Claude’s active temporal drift came in around 10%, among the lower figures in the test. But Claude fails differently: rather than substituting stale content for current information, it frequently declines — flagging that it can’t confirm whether a claim falls within the requested time window. That behavior comes from Anthropic’s Constitutional AI framework, which trains the model to acknowledge uncertainty rather than paper over it. From an accuracy standpoint, this is the right call. From a practical standpoint, it means Claude is less useful for tasks that actually require live information — it would rather say nothing than say something potentially wrong.
Grok — Best temporal accuracy, but a different caveat
Grok’s temporal drift rate came in below 5%, the most stable performance in the test. The reason is architectural: Grok ingests X’s real-time data stream natively, with timestamps embedded at the pipeline level before the model ever touches the content. The temporal anchoring problem is solved upstream, not during generation. This is a structural advantage that can’t be replicated by prompting or preference tuning — a model with a strong “truth-seeking” training objective but a standard semantic search retrieval layer would likely still drift significantly. What matters is the data pipeline.
That said, the advantage has a real ceiling. X is a high-density, high-noise environment. In roughly 8% of test runs, Grok’s output was temporally accurate but sourced from unverified posts or ideologically charged discussions. Getting the timestamp right is not the same as getting the story right. These are separate dimensions of reliability, and Grok’s strength on the first doesn’t carry over automatically to the second.
· · ·
Practical Takeaways
On tool selection
For tasks where recency is the primary constraint — breaking news, 24-hour intelligence summaries, real-time competitive tracking — Grok currently has the most consistent temporal accuracy. But that’s a narrow claim. Temporal accuracy and factual accuracy are different things, and Grok’s source pool carries its own reliability risks. For deep analytical work where recency pressure is lower, Claude and Gemini Deep Research each have real strengths, but both require independent verification of any time-sensitive claims.
On verification habits
· Any AI output containing “today,” “just announced,” “breaking,” or similar present-tense markers should trigger a verification reflex — regardless of which model generated it.
· Ask the model for exact sources and publication timestamps, then spot-check at least the most consequential claims.
· In high-stakes contexts, treat any LLM’s time-sensitive output as a lead, not a conclusion.
On calibrating your skepticism
The more fluent and confident an output sounds, the more discipline it takes to verify it. That’s counterintuitive — but it’s exactly the dynamic that makes temporal hallucination dangerous. The model that writes the most convincing briefing isn’t necessarily the one telling you what happened today.
· · ·
The Underlying Question
Temporal hallucination isn’t purely an engineering problem. It reflects a design choice that runs through the entire stack: is the model optimized to make you feel informed, or to actually inform you?
Most of the time, those two things align. But in the specific domain of time-sensitive information, they can come apart — and when they do, a model trained to prioritize helpfulness will fill the gap with whatever sounds most plausible, while a model trained toward epistemic honesty will tell you it doesn’t know.
Trust in an AI assistant shouldn’t rest on how confident it sounds. It should rest on whether it tells you when it’s uncertain. Those are not the same thing.
The architecture gap between models will likely narrow over the next two years as real-time data integrations become more common and epistemic humility gets more attention in alignment training. But in the meantime, understanding why these differences exist — and adjusting your verification habits accordingly — is the most practical thing anyone relying on AI for time-sensitive decisions can do.
Methodology note: Data reported here reflects the author’s observational testing conducted in February–March 2026. Each model was run 50 times using a uniform prompt, with all outputs manually reviewed for temporal accuracy. This is a directed evaluation of time-sensitive task performance, not a standardized measure of overall hallucination rate. All models update continuously; findings may not generalize across versions or use cases.