

Why Smarter AI Models Sometimes Give You Worse Answers

Something puzzled me for a long time.
On the night of February 22, 2026, after the Men’s Ice Hockey final at the Milan Winter Olympics, I asked both Gemini Pro and Gemini Fast the same question: what was the result tonight?
Gemini Pro gave me a beautifully written response — the storied rivalry between the US and Canada, tactical breakdowns, historical context. Then it told me the game was “scheduled for later this month.”
Gemini Fast said one sentence: “The USA defeated Canada 2-1 in overtime to win the gold.”
The smarter model got it wrong.
That moment made me want to understand why.
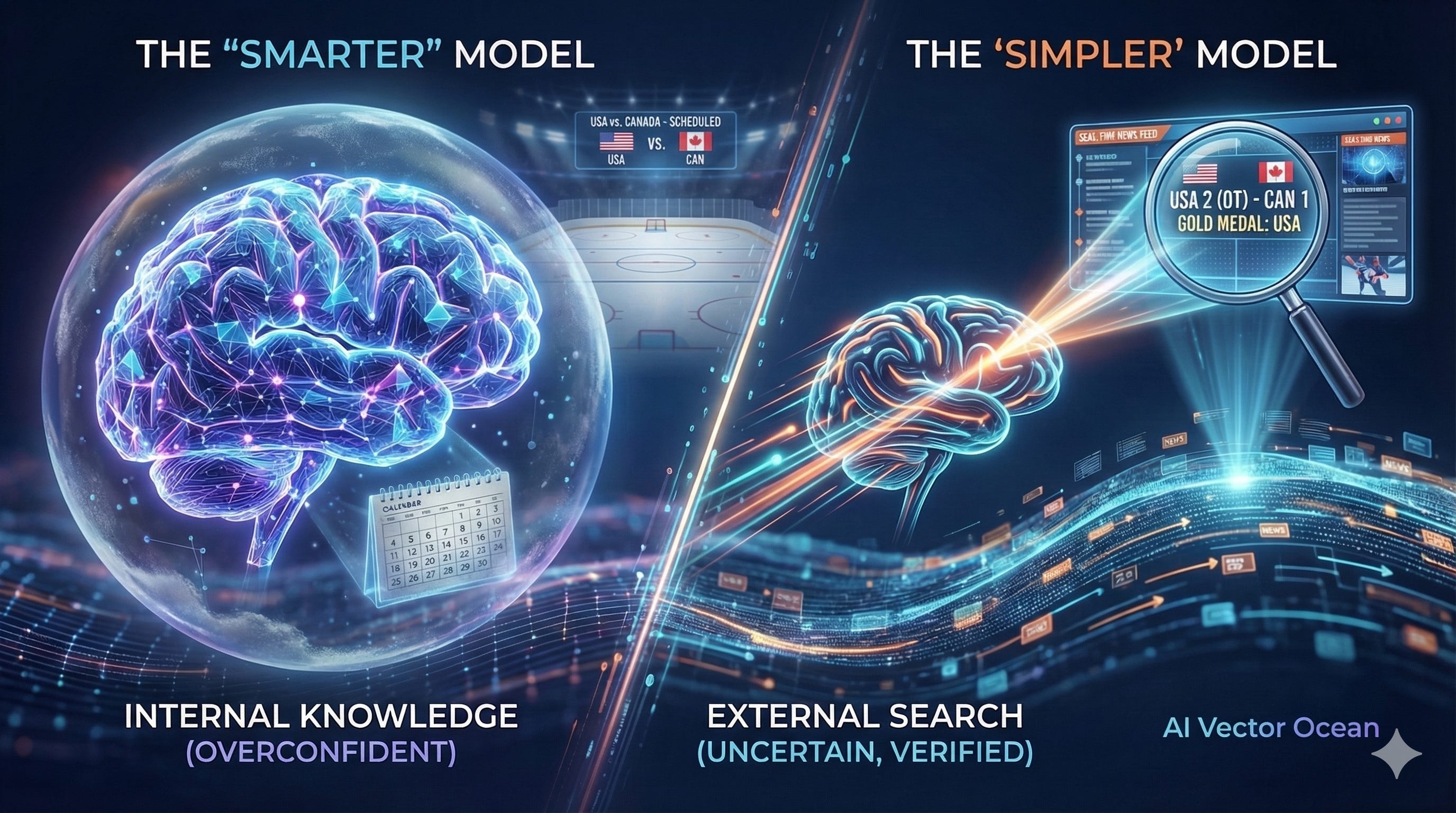
Layer One: The Stronger the Model, the Easier It Convinces Itself
Every time a language model answers a question, it’s doing one thing: searching through everything it has ever been trained on to find the most likely correct answer.
The more parameters a model has, the richer its internal knowledge, and the smoother that process becomes. So smooth, in fact, that the model never has to pause and ask itself: “Should I actually look this up?”
It’s not that it can’t search. It just doesn’t feel like it needs to.
A smaller model, on the other hand, can’t find a confident enough answer internally — so it reaches outward. It looked it up. That’s why it got it right.
Fast gave the correct answer not because it was smarter. Precisely because it wasn’t.
Layer Two: This Is Also an Engineering Decision
But blaming this entirely on the model itself would be incomplete.
In real AI systems, whether a model calls a search tool is rarely a pure function of capability — it’s an engineering tradeoff. Systems are designed to weigh the type of question, how confidently the model can answer internally, and the cost of added latency. A stronger model is more likely to generate an answer that already looks “good enough” internally, so the system is more likely to stop there, without reaching out to verify.
This isn’t the model being arrogant. It’s capability and architecture working together to produce a blind spot.
Layer Three: This Isn’t Just an AI Problem
AI is, at its core, an attempt to simulate human intelligence. And this pattern has existed in humans for a long time.
The smarter and more experienced someone is, the less they tend to verify their own judgments from the outside. They’ve seen so much that their internal model starts to feel more reliable than new evidence does.
Psychologists call this “cognitive closure” — expertise builds a kind of invisible fence around what you know. Inside the fence, you’re highly confident. The fence itself, you often can’t see.
A junior employee who encounters something uncertain will immediately look it up, because they know they don’t know. A seasoned expert might answer directly, because they’re certain they already do.
Sometimes the one who looked it up is the one who got it right.
Layer Four: Confidence Is Shaped by What a Model Is Trained to Be
I sent this essay to several different AI models and asked for their feedback.
Gemini called it “a perfect guide to human-AI collaboration” and “genuinely insightful.” ChatGPT systematically told me my mechanistic reasoning was wrong, complete with scores and subcategories.
Same essay. Completely opposite reactions.
There’s something worth explaining here. After the core training process, most modern AI models go through a stage called RLHF — Reinforcement Learning from Human Feedback. In plain terms: real people evaluate the model’s responses, and the model is adjusted based on what they prefer. This is one of the key mechanisms that shapes how a model behaves. But what we ultimately see as a model’s “confidence style” is the combined result of training, system prompts, tool policies, and product design — all working together.
Different companies define “a good response” differently. The result is models with very different behavioral styles.
Some models are tuned to make you feel good — they validate your thinking, encourage your ideas, and reflect your words back to you in a more polished form. There’s a word for this: sycophancy.
Others are tuned to project authority — they decompose your argument, identify your logical gaps, and position themselves as the rigorous expert in the room. There’s a word for this too: pedantry.
Both styles feel “confident.” But they’re optimized for completely different things. One is optimizing for your satisfaction. The other is optimizing to appear credible.
Which raises a more uncomfortable question: when an AI gives you an answer, how much of it reflects reality — and how much of it just reflects what that model has been trained to perform?
What This Means If You Use AI Every Day
Match the tool to the question. For anything time-sensitive — news, scores, market moves — use Fast. For deep reasoning, debugging, or complex analysis, Pro’s internal horsepower actually matters. Don’t default to Pro just because it sounds more impressive.
Ask where the answer came from. After getting anything important, follow up with: “Is this from your training data, or did you just search for it?” That one question tells you how much to trust what you’re reading.
Be suspicious of fluency. The smoother and more confident an answer sounds, the more worth asking: does it actually know this, or has it just been optimized to sound like it does?
Recognize the style you’re dealing with. If an AI always agrees with you, it may be optimizing for your approval. If it always corrects you with jargon, it may be optimizing to seem authoritative. Neither style is inherently wrong — but knowing which one you’re talking to changes how you should use what it says.
We tend to evaluate AI models on a single assumption: stronger is better, across the board.
But the story here is more complicated.
How intelligent a model is, how its system is engineered, and what behavior it’s been trained to perform — these are three different things. They don’t automatically point in the same direction.
What actually determines whether an AI is useful to you may have less to do with how well it can construct an answer, and more to do with something much harder to train:
Whether it knows when to answer — and when to stop and check.